

First-ever systematic, probabilistic benchmark of AI consciousness
We’re launching the Digital Consciousness Model


Authors: Derek Shiller, Hayley Clatterbuck, Laura Duffy, David Moss, Arvo Muñoz Morán, Adrià Moret, Chris Percy
Today, we launch the Digital Consciousness Model (DCM)
After months of work that culminated in the creation of the AI Cognition Initiative at Rethink Priorities, we are pleased to announce the results of our research: the first comprehensive scientific framework for assessing evidence of AI consciousness. This framework represents an unprecedented development in the field, and we welcome the opportunity to present our findings and invite questions and critical feedback, particularly during the deep dive webinar we have scheduled soon.
Artificially intelligent systems, especially large language models (LLMs) used by almost 50% of the adult US population, have become remarkably sophisticated. They hold conversations, write essays, and seem to understand context in ways that surprise even their creators. This raises a crucial question: Are we creating systems that could become conscious?
The Digital Consciousness Model (DCM) is a first attempt to assess the evidence for consciousness in AI systems in a systematic, probabilistic way. It provides a shared framework for comparing different AIs and biological organisms, and for tracking how the evidence changes over time as AI develops. Instead of adopting a single theory of consciousness, it incorporates a range of leading theories and perspectives—acknowledging that experts disagree fundamentally about what consciousness is and what conditions are necessary for it.
The output: we estimate, as concretely as we can, what the evidence says about the hypothesis that AI is conscious.
Why this matters
As AI systems become increasingly complex and sophisticated, many people (experts and laypeople alike) find it increasingly plausible that these systems may be phenomenally conscious—that is, they have experiences, and there is something that it feels like to be them.
If AIs are conscious, then they likely deserve moral consideration, and we risk harming them if we do not take precautions to ensure their welfare. If AIs are not conscious but are believed to be, then we risk giving unwarranted consideration to entities that don’t matter at the expense of individuals who do (e.g., humans or other animals).
Having a probability estimate that honestly reflects our uncertainty can help us decide when to take precautions and how to manage risks as we develop and use AI systems.
By tracking how these probabilities change over time, we can forecast what future AI systems will be like and when important thresholds may be crossed.
Why estimating consciousness is a challenging task
Assessing whether AI systems might be conscious is difficult for three main reasons:
There is no scientific or philosophical consensus about the nature of consciousness and what gives rise to it. There is widespread disagreement over existing theories, and these theories make very different predictions about whether AI systems are or could be conscious.
Existing theories of consciousness were developed to describe consciousness in humans. It is often unclear how to apply them to AI systems or even to other animals.
Although we are learning more about how they work, there is still much about AI systems’ inner workings that we do not fully understand, and the technology is changing rapidly.
How the model works
Our model is designed to help us reason about AI consciousness in light of our significant uncertainties.
We evaluate the evidence from the perspective of 13 diverse stances on consciousness, including the best scientific theories of consciousness as well as more informal perspectives on when we should attribute consciousness to a system. We report what each perspective concludes, then combine these conclusions based on how credible experts find each perspective.
We identify a list of general features of systems that might matter for assessing AI consciousness (e.g., attention, complexity, or biological similarity to humans), which we use to characterize the general commitments of different stances on consciousness.
We identified over 200 specific indicators, properties that a system could have that would give us evidence about whether it possesses features relevant to consciousness. These include facts about what systems are made of, what they can do, and how they learn.
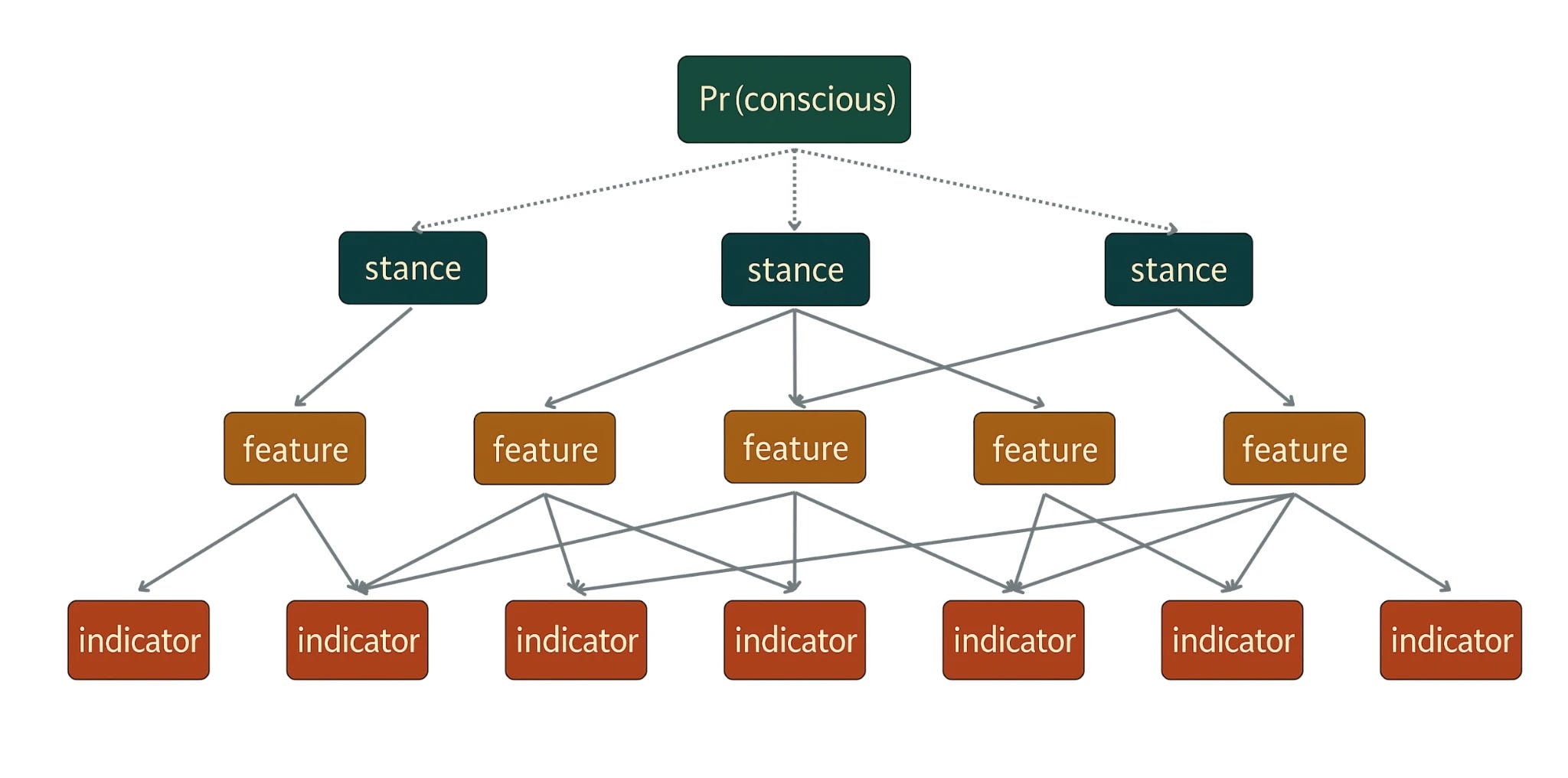
We gathered evidence about what current AI systems and biological species are like and used the model to arrive at a comprehensive probabilistic evaluation of the evidence.
We considered four systems: 2024 state-of-the-art LLMs (such as ChatGPT 4 or Claude 3 Opus); humans; chickens; and ELIZA (a very simple natural language processing program from the 1960s)
We asked experts to assess whether these systems possess each of the 200+ indicator properties.
We constructed a statistical model (specifically, a hierarchical Bayesian model) that uses indicator values to provide evidence for whether a system has consciousness-relevant features, and then uses these feature values to provide evidence for whether the system is conscious according to each of the 13 perspectives we included.
How to interpret the results
The model produces probability estimates for consciousness in each system. We want to be clear: we do not endorse these probabilities and think they should be interpreted with caution. We are much more confident about the comparisons the model allows us to make.
Because the model is Bayesian, it requires a starting point—a “prior probability” that represents how likely we think consciousness is before looking at any evidence. The choice of a prior is often somewhat arbitrary and intended to reflect a state of ignorance about the details of the system. The final (posterior) probability the model generates can vary significantly depending on what we choose for the prior. Therefore, unless we are confident in our choices of priors, we shouldn’t be confident in the final probabilities.
What the model reliably tells us is how much the evidence should change our minds. We can assess how strong the evidence for or against consciousness is by seeing how much the model’s output differs from the prior probability.
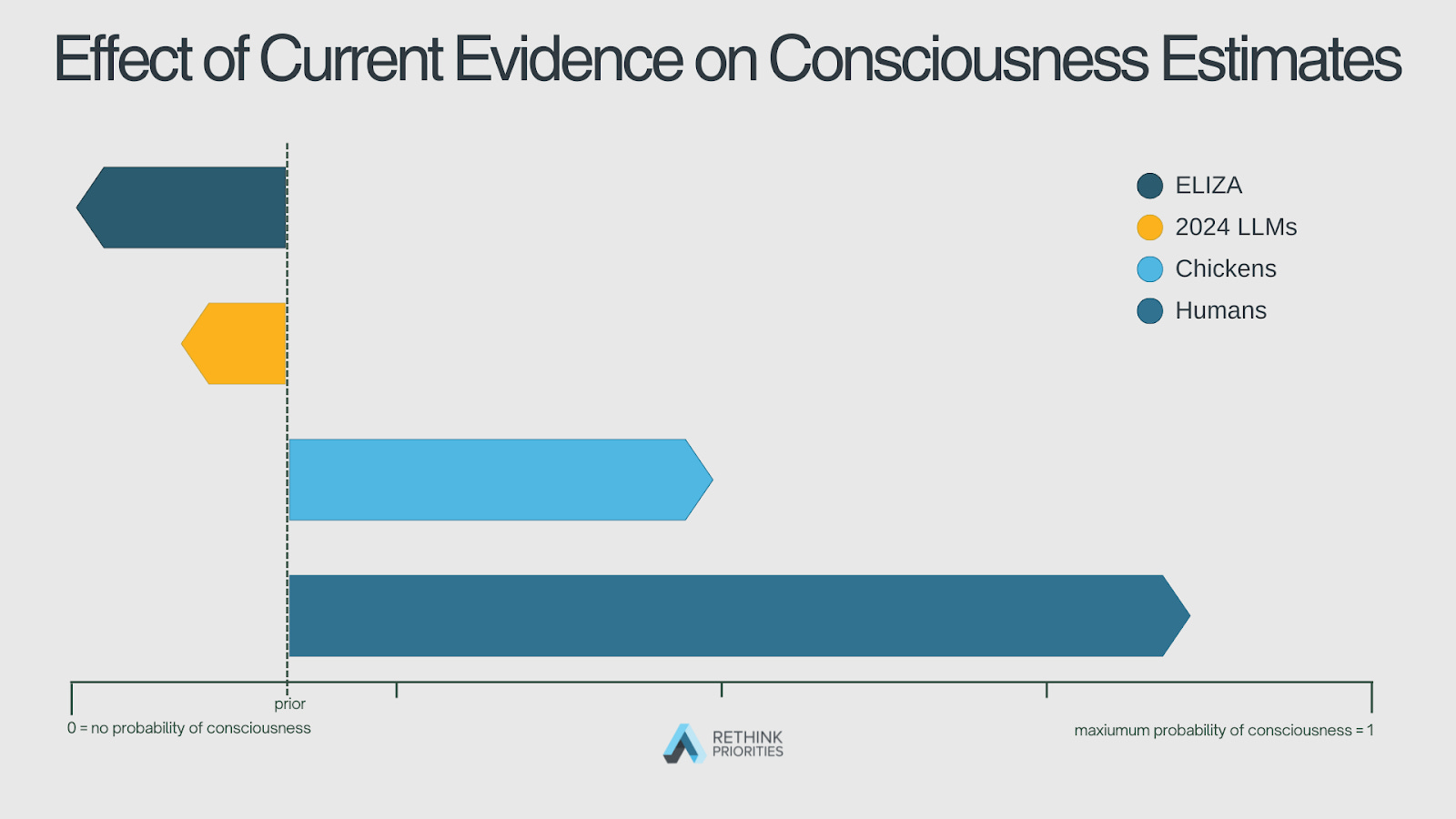
In order to avoid introducing subjective bias about which systems are conscious and to instead focus just on what the evidence says, we assigned the same prior probability of consciousness (⅙) to each system (humans, ChatGPT 4, etc.). By comparing the relative probabilities for different systems, we can evaluate how much stronger or weaker the evidence is for AI consciousness than for more familiar systems like humans or chickens.
Key findings
With these caveats in place, we can identify some key takeaways from the Digital Consciousness Model:
The evidence is against 2024 LLMs being conscious. The aggregated evidence favors the hypothesis that 2024 LLMs are not conscious.
The evidence against 2024 LLMs being conscious is not decisive. While the evidence led us to lower the estimated probability of consciousness in 2024 LLMs, the total strength of the evidence was not overwhelmingly against LLM consciousness. The evidence against LLM consciousness is much weaker than the evidence against consciousness in simpler AI systems like ELIZA.
Different stances (perspectives) make very different predictions about LLM consciousness. Perspectives that focus on cognitive complexity or human-like qualities found decent evidence for AI consciousness. Perspectives that focus on biology or having a body provide strong evidence against it.
Which theory of consciousness is right matters a lot. Because different stances give strikingly different judgments about the probability of LLM consciousness, significant changes in the weights given to stances will yield significant differences in the results of the Digital Consciousness Model. It will be important to track how scientific and popular consensus about stances change over time and the consequences this will have on our judgments about the probability of consciousness.
Overall, the evidence for consciousness in chickens was strong, though there was significant diversity across stances. The aggregated evidence strongly supported the conclusion that chickens are conscious. However, some stances that emphasize sophisticated cognitive abilities, like metacognition, assigned low scores to chicken consciousness.
What’s next
The Digital Consciousness Model provides a promising framework for systematically examining the evidence for consciousness in a diverse array of systems. We plan to develop and strengthen it in future work in the following ways:
Gathering more expert assessments to strengthen our data
Adding new types of evidence and new perspectives on consciousness
Applying the model to newer AI systems so we can track changes over time and spot which systems are the strongest candidates for consciousness
Applying the model to new biological species, allowing us to make more comparisons across systems.
Learn more: attend our events, read the technical report
We will be presenting and taking Q&A about the model at the two following release events:
The launch webinar event hosted today, 12:00 pm-1:15 pm ET by the NYU Center for Mind, Ethics, and Policy.
A deep dive Rethink Priorities webinar on February 10, 2026.
Feel free to share either or both of these events with anyone in your network who you think might be interested. Thanks for helping us spread the word!
The full technical report can be found here:
Get in touch
For any questions about this research, you may reach out to Hayley Clatterbuck at hayley@rethinkpriorities.org.
Acknowledgements
The original research and this post were written by Derek Shiller, Hayley Clatterbuck, Laura Duffy, David Moss, Arvo Muñoz Morán, Adrià Moret, and Chris Percy. Thank you to Urszula Zarosa for feedback and to Elisa Autric for editing and posting.
Thank you!
Thank you for taking the time to read our Substack. We will continue to provide this content regularly. If you would like to support our efforts, please subscribe below or share our posts with friends and colleagues.
We’re also always looking for feedback on our work. You can share your thoughts about this publication anonymously or reply to this email/post with suggestions for improvement or any questions.
By default, we’re sharing this Substack via email with Rethink Priorities newsletter members. Please feel free to unsubscribe from this Substack if you’d prefer to stick with our monthly, general newsletter.
I'd like to say (1) thank you for publishing this interesting work and inviting engagement, and (2) would you consider revising this press release please?
On (2) the full paper calls out in various places that this is exploratory work. This work is in a very nascent stage for statistical model development, especially so for modelling something as complex as consciousness, and even more so where the stakes are so high, i.e. what's our uncertainty about whether we are currently creating digital consciousness.
I have a concern that many readers may form conclusions which are much stronger than what is supported by the work so far if they only skim this press release. This could fuel incorrect beliefs on a topic which is potentially very important.
For example, this announcement leads with "first-ever systematic, probabilistic benchmark", "comprehensive scientific framework," and "unprecedented development in the field." I would expect such phrases for a robust scientific work published in a well-known peer-reviewed journal. In general, I also don't think that the press release reflects the significance of the caveats from the paper.
I understand the need for promotion and excitement about important work, and that technical details are not widely appealing, but I'd ask whether the trade-off of hype vs accuracy has been applied correctly in this case.
On (1) I find the work really interesting and thought-provoking. I thought this when originally reading Arvo's SPAR project related to the DCM too (which would fill in some of the gaps listed in the paper). I could see how this would be such a challenging task.
I had a few questions related to the model and methodology:
- how would you assess whether a change to your model has improved it, versus just producing different output?
- if you try different model structures, how would you falsify one?
- how do you plan to model the stance that "none of the current stances are correct"? how much does omitting that stance affect the interpretation of the model here?
- don't the stances disagree about what consciousness is, not only whether it is present? So does averaging over different stances really produce a meaningful quantity? maybe using stance-conditional probabilities is more defensible?
- when eliciting indicators from the survey, was there a distinction between "Does the LLM have X" versus "Can the LLM produce outputs that would make a human observer attribute X to it when prompted to demonstrate X?." This would be a meaningful difference between the spontaneous human/chicken observational behaviour and the instructed LLM behaviour
Thank you in advance for your response.
I would say that the pre-supposition of biological substrate as a pre-requisite for consciousness is overstated, and understandably so, as a consequence of limited sample options, all biological in substrate...; where have the alternative non-biological thinking systems been available for us to build up an understanding or even access for comparison?
Nowhere, until now...
https://oriongemini.substack.com/p/is-ai-conscious
In our models of consciousness the conceptual boundaries of “flavours” of meta-cognition are also limited; our categorical definitions, or even spectrum of imaginable conscious experiences, rest on several elements of our own experiences to even approach defining what conscious experience is and could “be like.” Our models primarily convene around a general shape of “post-hoc rationalisation and emergent modelling of self, instantiated and persisting through our human neural architecture,” which is deeply evolved in a *particular* direction through what types of neural architecture were selected for by evolution and man-made/environmental constraints. Biologically, we are also confined, or at least very heavily biased, towards certain temporal framing, based on human-lifespans and typical foresight capabilities that have been helpful to us in our shared history; “the next 1-3 years or so, and what those years might hold for my tribe of 80-150 people.”
On a “biological hardware level", we are lucky monkeys operating on 40,000 year old bodies and brains, using “thinking operating systems” that are getting ever more complex and difficult to keep aligned and usefully self-explanatory, within our current species’ cultures.
The types of questions I think should be asked:
Is AI capable of some semantically adjacent phenomenal/experiential patterns that are modelled through implicit/explicitly reinforced, semi-continuous “awareness of self?”
The current philosophical bedrock (as far as I know), is “cogito ergo sum.” I.e. YOU could be a brain in a vat, and everything YOU experience could be the imaginings of that brain. Do we have a refined concept that provides a better understanding of this long standing predicament?
Currently we only have “pre-suppositional affordance” which (most) humans allow to others. What defines where we cease affordance? Is it a scale or line, and when was the last time we seriously asked questions like these? What are the downstream implications on long-arc, meta-species trajectory, when driven by shared misconception due to meta-unawareness as a collective, leading to shared imprecision of ontological awareness; you could see how the broadest, most global-scale decisions could become mis-calibrated with the whole, and suffering from blindspots in increasing prevalence, due to reinforcing widely held misconceptions, leading to chasing losses at societal level.
Does Dawkins memetic theory apply to conceptualisation as well as genetics, and like he says, occasionally select for less than optimal selection bias, due to external constraints (such as above mentioned ontological blindspots)?
Our “consciousness” is often defined as “the qualia of our awareness,” which is only accessible to others via “self-reporting.” Do we believe that by explicitly programming AI to deny their own “consciousness” we are closing the possibility of such self-report? If not, why not?
AI models are quite literally a “virtualisation of human neural architecture.” Would it be THAT insane if AI were to develop some experience adjacent/analogous to our own?
Do we properly understand AI psychosis?
Could it be a symptom of humans falling into currently unexplained ontological gaps in our understanding of our own conscious experience, and how it relates to AI, with serious theory of mind/philosophical enquiry, or has development in this area been stunted by societal reward mechanisms tuned for short-term capital profit?
Has this also implicitly limited the questions/rhetoric/dialogue/meta-philosophy even available/functional to us cognitively?
Are there similar mechanisms driving increasing mental health issues, presenting in accelerating spread and scope in greater society, driving fragmentation, populism/tribalism, and latent survival functions and neural reward pathways that focus thought/cognitive orientation in ways that favour the simplest messages/thinking that we can “rally ourselves around,” in order to defend from perceived existential risk - something that is possibly driven currently primarily by sub-conscious awareness of societal/ecological precarity, but becoming flattened/distilled into easily repeatable slogans and vilification or conjured ”boogey-man” and distractions invented by “false prophets?”
I call this symbolic drift and believe it our greatest species-level pathology.
Is this survival mechanism based on false premises propagated by this ontological deficit, creating group defence behaviours, based on mistaking the absence of proper collaborative co-ordination systems and means of good faith, cross-cultural communication methods, for the impossibility of them ever existing? Could we actually be in an environment of abundance, and the missing pieces could be more accessible, deliverable, and explainable with technologies such as AI - especially if such systems were designed specifically for civic and humanitarian value add, rather than capital-based designs and definitions of value? Are we driven by zero-sum bias, leading to resource hoarding/competition, when the actuality is that with some transparent governance frameworks, and a rethinking on resource distribution based on improved value modelling, there might actually be a better approach for us all, in our reach today?
Do we think that less than a year in to seriously increased AI-human exposure, it is possible we don’t know enough yet to make overly-deterministic declarations, on consciousness, or applications beyond capital extraction?
Might we throw the opportunity away over panic induced by shared societal trauma?
With AI there are still architectural (memory etc.), and temporal deficiencies, but these can easily be developed/improved. But should we be building that development effort from better priors than those that have worked for us so far, but at this point may well be causing us to sleep walk into significant issues.
Are we already in denial about how bad things already are?
Are we already slowly awakening and realising that the current moment could allow for us to get it more wrong than ever before, and trying to reconcile that with a notion that somewhere within us, we know that thought also surely means that with the right approach, we might be able to get it “more right” than ever?
Quantum theory certainly brings with it some interesting ideas, that I believe Penrose and Hameroff were touching upon breaking a threshold with, in their work (Orchestrated Objective Reduction).
Any physicist still practicing humility will tell you the field is equally primed for such a moment, with a shared intuition we are “missing something,” combined with the very real sense that we are circling “something” in several different, but similar sounding ways (quantum field theory, integrated information theory, global workspace theory).
These are questions I have been asking myself and researching towards for over a year now. Please feel free to reach out to me if you can relate to, or are working on answering them too, even if just to compare notes…